&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
“Auth” demystified: authentication vs authorization
Jul 26th, 2023

Noa Shavit
Authorization
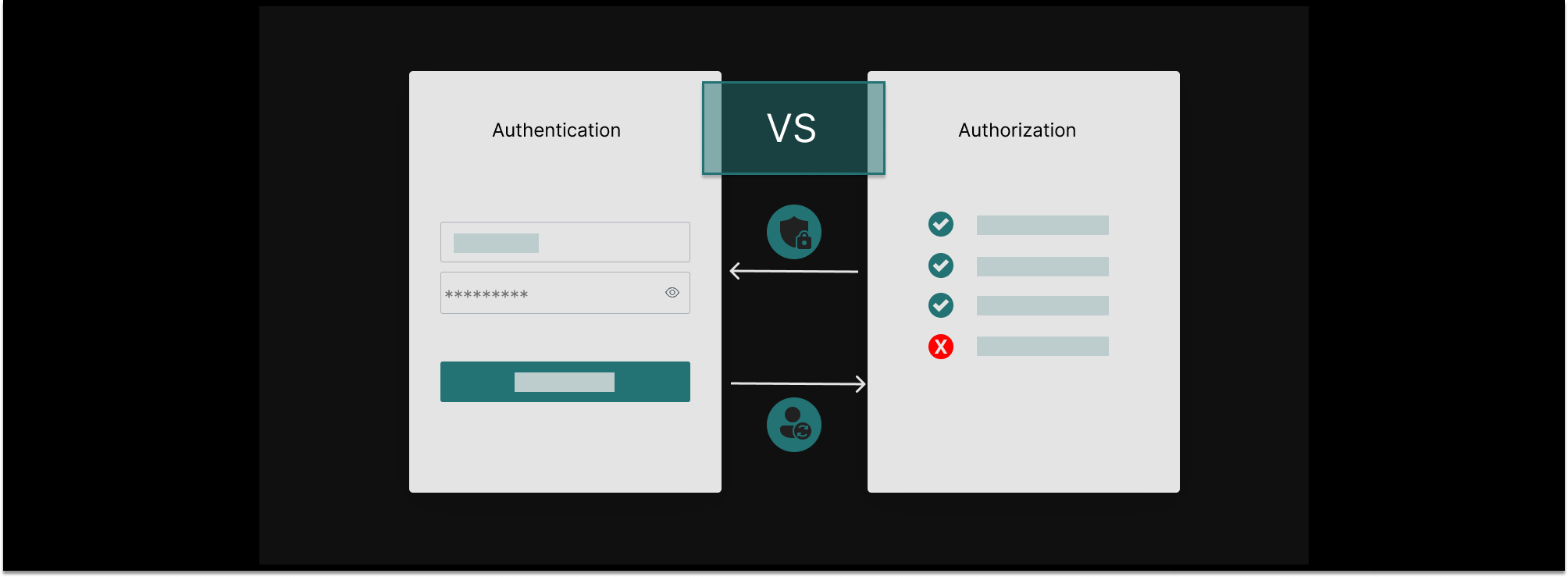
People tend to lump authorization and authentication together and refer to them as “auth.” In fact, one of the most widely held misconceptions is that authorization and authentication are the same, or something your identity provider does. It also doesn't help that certain authentication vendors blur the line by offering their versions of access controls. But, the reality is that authentication and authorization are two distinct processes with vastly different challenges and architectural needs.
Authentication is a solved problem. We have well-defined standards, protocols, and established vendors that offer off-the-shelf solutions. Authorization, on the other hand, is far from solved. There are no standard protocols or frameworks, so every app must build its own system. To make matters worse, authorization is a complex problem, one that requires a distributed systems architecture with real time access checks to get right. Read on for all the details.
Authentication
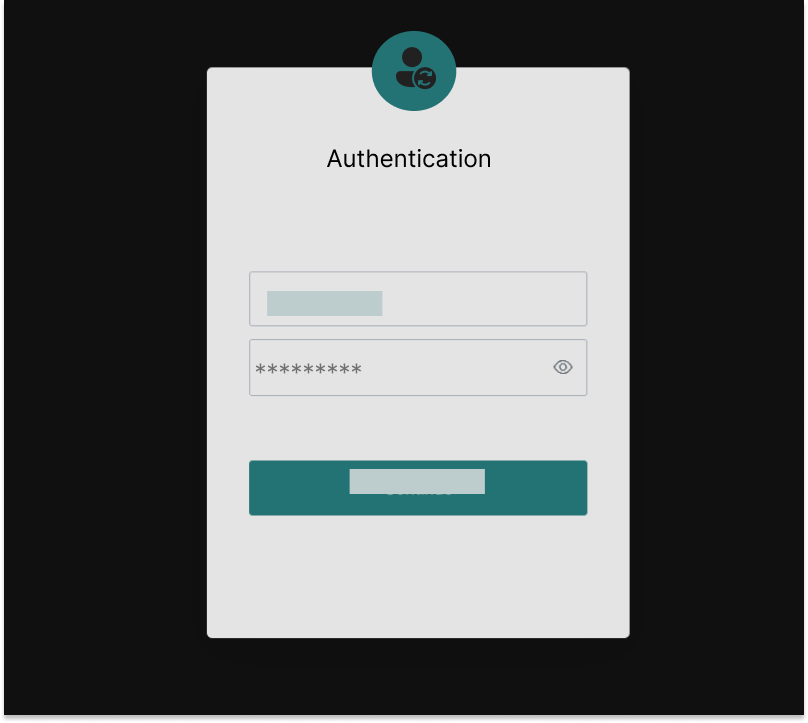
Authentication focuses on the user’s identity. The goal is to verify that the user is who they claim to be. This is a process that runs once per user session and ends with a secure login. It’s the first gatekeeper of your application, but it shouldn’t be the last.
Does the information provided match the identity information in the user directory? Is the user using a registered device from a known location? Has the user proven their identity with multiple factors? These are the types of questions authentication platforms evaluate to assess if the user should be able to log-in and access the application.
Authentication platforms are also known as identity providers (IDPs). They provide tools to securely collect and store user information, such as single sign-on, passwordless access, multi-factor authentication, and user management. Example IDPs include Okta, Auth0, AWS Cognito, Azure Active Directory, and PingID.
Some IDPs have their versions of access control, where roles that were configured in the system are embedded as scopes in access tokens. This might seem like a simple way to use role-based access control, but it has one main disadvantage that outweighs the benefits: the user will continue to have access for as long as the token is valid, even if you no longer want them to.
More about the differences between scopes vs permissions and why not to embed permissions in access tokens.
Modern authentication
A new wave of authentication companies have emerged. These services are not only cloud-native but also tend to be more specialized than their predecessors. WorkOS, 1Kosmos, and Clerk are great examples of modern identity services that specialize in one aspect of identity, e.g. SSO, passwordless access, and user management.
This is all possible because the tech industry banded together to form authentication standards and protocols, like OpenID Connect, SAML, OAuth 2, and JWT, which have made it so that we have an interoperable identity fabric. Thanks to this identity fabric, users can seamlessly access any application that supports those standards and protocols.
The main challenges of authentication
Within this mature ecosystem, the remaining challenges revolve around password security, SMS spoofing, and device security. Weak passwords, reused passwords, SMS spoofing and other ways in which threat actors can trick the user to provide them with access to their accounts, not to mention device hacking, are the main challenges of user authentication systems.
Provisioning and deprovisioning accounts is also a challenge. Once a user leaves the organization they should no longer have access to their various accounts. If they can still access their accounts, so can threat actors. This adds a layer of administrative overhead to the authentication and identity security process for most organizations. Some vendors provide automatic provisioning and deprovisioning of accounts based on rules the organization defines, and some support global “disable” flags on users, automatically revoking access to every system.
To sum up, Authentication is mostly a solved problem. We have consistent standards for secure authentication and various vendors that have built standards-based authentication tools that provide customers with secure login and user management.
The state of authorization in 2023 is widely different.
Authorization
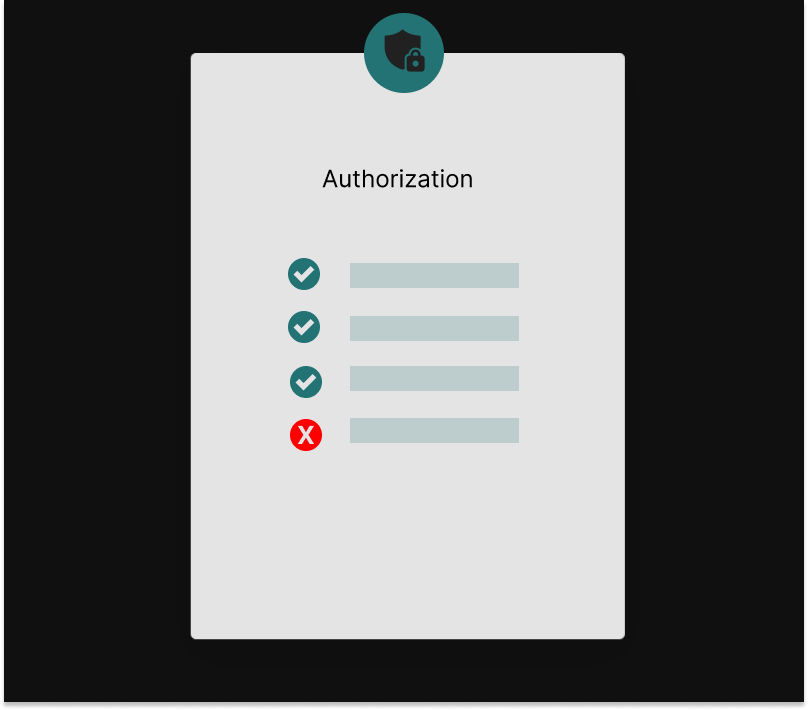
Authorization focuses on the actions available to the user. It begins once the user has securely logged into the system and determines what they can see and do in the context of the application.
It’s important to note that the authorization process happens continuously throughout a session, as the user is engaging with the system. Can the user access a certain page? What menu items should be visible to them? Which resources? These are the type of questions application authorization systems answer.
Unlike authentication, there are no standards or protocols for authorization. So today, every application is forced to reinvent the wheel and build their own authorization system. This also means that every app essentially authorizes differently, and understands authorization differently. More about that here.
Coarse-grained vs fine-grained access controls
One of the most popular authorization models is known as role-based access control (RBAC). In this model, permissions are aggregated into roles that are assigned to users or groups of users. These roles tend to coincide with a business objective (e.g a IT administrator should be an “admin” on most applications, while a freelance content creator should only be the “editor” of the CMS). More to the point, these roles tend to be cross-application, where an “editor” can edit any resource and an “admin” can delete any resource. These are coarse-grained roles. And coarse-grained roles tend to be overprovisioned, encompassing anything and everything a user might ever need.
A zero trust approach requires we shift from standing permissions and overprovisioned roles to fine-grained controls over protected resources. The principle of least privilege is key to zero trust. It stipulates that users should only have access to what they need at that moment to perform their function. Fine-grained controls over access to individual resources is crucial if you want to adhere to this principle.
Attribute-based access controls (ABAC), relationship-based access controls (ReBAC), and policy-based access controls (PBAC) are all fine-grained authorization models. ABAC systems use user, resource, and environment attributes to determine access, while ReBAC models base access on the relationships between users and resources.
Modern authorization
Over the past few years, a new wave of authorization vendors has emerged that provide various degrees of fine-grained access controls. A few open-source projects have been launched as well, including Open Policy Agent (OPA) and Topaz, but they all have their own approach to authorization and ways of defining and enforcing access controls.
There are two technical approaches to modern authorization that are growing ecosystems around them: policy-as-code and policy-as-data. They are similar in that both approaches advocate decoupling authorization logic from the application code. But they also have differences.
In policy-as-code systems, the authorization policy is written in a domain specific language, and stored and versioned in its own repository like any other code. OPA is one well known example of this approach. It is a CNCF graduated project that is mostly used in infrastructure authorization use cases, such as k8s admission control. It provides a great general purpose decision engine to enforce authorization logic, and a language called Rego to define that logic as policy.
The policy-as-data approach determines access based on relationships between users and the underlying application data. Rather than rely on rules in a policy, these systems use the relationships between subjects (users/groups) and objects (resources) in the application.
Google’s Zanzibar, the authorization system behind Docs and other Google apps, is a great example of this approach. Resource owners can share their assets with others and determine what actions will be available to them.
OPA is flexible enough to support RBAC and ABAC systems. But it has no “opinions,” so you have to create your authorization model from first principles. It also doesn’t have a data plane, so getting authorization data to the decision point is an exercise left for the implementing developers.
Zanzibar, on the other hand, is certainly opinionated, and can be applied to a wide range of use cases. But it’s not a single open source project, or even a specification. It’s a paper that describes a set of ideas, with many different interpretations and implementations. Each implementation has its own schema language to describe object types and their relationships.
Indeed, the Zanzibar ecosystem would greatly benefit from some commonality and re-use across implementations. Ironically, since OPA is a single implementation, it has actually solved these problems: there is a well-defined query API for evaluating authorization rules, a well-specified language for writing those rules, a standard way to express decision logs, and extensibility points for vendors to add features.
Thankfully, these approaches aren’t mutually exclusive. There are some systems that support both approaches to various degrees. Topaz is one such system. It is a standalone open-source authorization system that combines the best of OPA and Zanzibar. You can deploy it in your cloud today and easily add fine-grained access controls to your applications. Here’s the code.
The main challenges of authorization
Fine-grained authorization is nothing if not challenging. It is a far more complex issue than authentication for a few reasons:
- It is on the critical path of every application request: following the principle of continuous monitoring, modern authorization systems verify access prior to providing it, as the user engages with the application. Based on our data, most applications make two or more access calls per frontend interaction. So decisions need to be made quickly to not impact performance.
- Local decision points: the decision engine, also known as the authorizer, must sit as close to the application as possible to avoid round trips across the web that will impact performance.With that said, we want to manage all of our authorizers from one place to simplify management and administration.
- Central management: managing authorizers centrally ensures consistency, reusability of policies, and simplifies administration and governance. Note that this need for local enforcement with central management is a distributed systems problem, which is an undertaking some organizations cannot afford building on their own.
- Real-time enforcement over fresh data: the only way to ensure we are not providing access over stale data is to automatically push any changes to user information, resource context, policy, or data to all of the local authorizers in real-time. To do this you need to build a high-speed data fabric that syncs changes to any authorization information to all the local decision points in real-time.
- Lack of standards and protocols: if the challenges above weren’t enough, today there are absolutely no standards, protocols, or battle-tested developer tools for building fine-grained access control systems. As a result, not only does every application have to build its own application authorization system, it also interprets authorization it differently.
Authentication vs authorization
The table below summarizes of the main differences between user authentication and application:
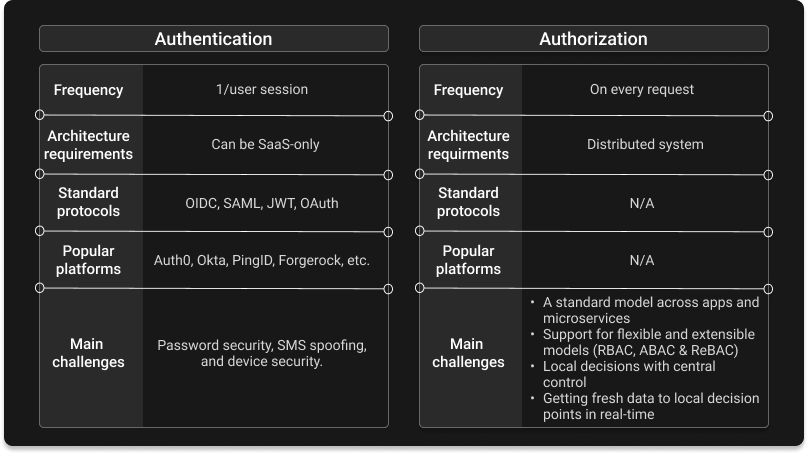
Conclusion
Authentication and authorization are two processes that protect applications against a damaging breach. Authentication guards the front gate, while authorization protects the rooms of the castle, limiting the potential blast radius by restricting what users can do.
While the two work together, they are very different. Authentication happens once per session, while authorization is on the critical path of every application request. There are identity standards, protocols, and an interoperable identity fabric. There are no ubiquitous standards, protocols, and policy languages for access control.
A zero trust approach to application security requires fine-grained authorization, potentially extending all the way to individual resources. Fine-grained access controls improve an application’s security posture by adhering to the zero trust principles of least privilege and continuous verification. Access is verified prior to being granted, based on real-time data, and it is limited to what the user absolutely needs at that time.
There are two technical approaches to fine-grained authorization: policy-as-code and policy-as-data, and a few projects that support both approaches to various degrees. Topaz is one. It uses OPA as a decision engine and language, and also has a built-in relationship database based on the Zanzibar model, allowing developers to enjoy the best of both worlds.
That’s it for now, as always we’d love to hear what you think! Drop us a line here or join our community Slack channel.
Noa Shavit
Head of Marketing


Related Content

5 Ways to Fix Your Broken Authorization System
Authorization is broken. What would a great developer solution look like? Here are the five principles that application authorization platforms for developers should follow.
Aug 2nd, 2023

The future of IAM is fine-grained
Identity is mostly a solved problem, access is far from that. It only makes sense for the IAM industry to tackle the most difficult problem we face today, namely how do we limit the potential damage of a breach.
Aug 9th, 2023

Auth in everyday terms
“Auth” tends to be the term used to describe the process of Authentication and Authorization. But these are two distinct processes. Don't worry, even some experts make this mistake. In this post, we provide a real-world analogy that explains the differences between the two.
Aug 16th, 2023