&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
Modern access control explained
May 17th, 2023

Noa Shavit
Authorization

We recently had the opportunity to chat with the Amazic.com team about modern application authorization. We covered the differences between authentication and authorization, the evolving challenge of application authorization, the two approaches to cloud-native access control, and the open-source project that marries the best of both.
Tune into Aserto CEO, Omri Gazitt, describing the cloud-native authorization landscape, or read all about it below:
Authentication vs Authorization
There is a common misconception about authorization and authentication. People tend to use the two terms interchangeably, or lump them up as “auth,” but they are two distinct processes.
Authentication is about proving that a user is who they claim to be. Back in the days of operating systems, this was done with a user ID and password. Today we use biometrics, passwordless access, and magic links, but ultimately it's the same function. Authentication focuses on the identity of the user, happens once a session, and ends at secure login.
Authorization kicks in after login, and happens every time the user performs an action. It determines what a user can do in the context of the application based on user, policy, and resource information.
Confusing, right!? It also doesn’t help that some IAM vendors mingle these concepts together in their messaging and offer their version of authorization tools. These tools tend to use authentication standards, like OIDC and OAuth 2.0, which aren’t the right building blocks for authorization. OAuth scopes baked into access tokens have the potential to outlive the intended lifespan of the access. You can get into trouble when you treat your authentication system as an authorization system. For more about the reasons why, go here.
Now that we have a better understanding of what authorization is, we can review why it’s so hard to get right.
The evolving challenge
Back in the day of operating systems, authorization wasn’t much of an issue. The operating system logged you in and verified that you had the right permissions to do what you were trying to do. It would check whether a user had read or write permissions on files or i-nodes, things like that. And application packages, such as SAP or Oracle, had roles that were implemented as groups in a global directory, like Azure Active Directory or LDAP. So both authentication and authorization were functions that were managed by the operating system. It was clunky, but it worked. It provided organizations with one place to go to configure and map users to groups and roles.
When software began moving to the cloud and away from operating systems, every vendor had to build their own authentication and authorization capabilities. The first thing that we did, as an industry, was to fix the authentication problem. We invented authentication protocols and standards, including OAuth 2.0, OpenID Connect, SAML, and JWT. And now we have an interoperable identity fabric.
At the same time, authorization hasn't moved forward at all. While authentication is mostly a solved problem, authorization is far from that. We truly believe that it is time that we unite as an industry to solve the hard problem of authorization, working alongside the people who already fixed the authentication problem. Authorization isn’t authentication, but it does complement it.
Organizations’ growing pain
Authorization is a much more complex problem today than it was 10 or 15 years ago. Back then, you had operating systems and monoliths. You had one place to map users to groups and roles, and a single codebase to sprinkle your logic into various places. Today, the situation is more complex. A startup will have at least a dozen microservices that need to be authorized. And as companies grow, it’s no longer in the single digits. Large organizations support a multitude of internal and external applications. Hundreds of applications, each with its own authorization system.
The shift to cloud computing and microservices based architectures has made authorization into the problem it is today. Not only has it moved from the operating system to the application, the onus for securing access to the application has shifted onto developers. It is on the developers to build and govern access control systems for their applications.
Building authorization for applications is hard. Most organizations don’t build authorization correctly. If they did, broken access controls wouldn't be #1 on the OWASP top 10 list of application security risks. Broken access control refers to any situation where a user has permissions over resources they shouldn’t. The issue is so prominent that a whopping 94% of sites reviewed by the OWASP exhibited some degree of broken access controls.
Administrating authorization is also a nightmare these days. Every application authorizes and exposes permissions and roles in a different way. As a result, the number of entitlements that IT administrators end up managing is the cross-product of applications and users. Misconfigurations are rampant, and over-provisioning is the norm. A zero-trust approach requires we follow the principle of least privilege. The user should only have access to what they need to perform their duty. To this end, we need better controls. We need fine-grained access controls.
Approaches to fine-grained access controls
Fine-grained access controls refers to the ability to limit user privileges to specific items, or resources within an application. Google Drive is a great example, a user can share specific files or entire folders with others. And file owners can also restrict the actions available to the shared users (view, comment, edit). These are examples of fine-grained access controls.
There are two approaches to fine-grained authorization that are starting to coalesce ecosystems around them: The Open Policy Agent (OPA) policy-based approach and the Google Zanzibar data-centric approach.
Open Policy Agent (OPA) is a CNCF graduated project that provides a general-purpose decision engine. It has also developed a domain specific policy language, called Rego. Policies are lists of access rules that the decision engine uses to make decisions. They are decoupled from application code, written using a domain-specific language, and stored and versioned in their own repository. This is known as “policy-as-code.”
Policy-as-code allows for separation of duties, enabling the handoff of the policy from developers to the security team who can own its evolution. This facilitates an agile workflow between the application teams, that no longer have to deal with authorization in their code, and security teams who can evolve the policy independently.
Google Zanzibar represents the data-centric approach. In this approach, authorization is based on the underlying application data, rather than a list of rules. Zanzibar is the unified authorization system behind many Google apps, including Drive, Cloud, Calendar, and others. It uses a relationship-based access control (ReBAC) model that bases access on the relationships between users and application resources.
ReBAC is a very opinionated model, where authorization is expressed as tuples of relationships between subjects and objects. To determine access, we need only traverse the graph to find the relationship between the user and the resource they are trying to access. Relationships can be as simple as “owner,” “member,” and “editor, or as complex as parent-child, containment, and even managerial relationships.
Authorization systems tend to follow one of the above approaches, either basing access on external policies or underlying data. Topaz is an open-source authorization project that marries the two, providing the best of Zanzibar and OPA.
Topaz open-source authorizer
We built an open-source project to address a gap in the market. OPA doesn't have a data plane. They leave getting the data to the decision point as an exercise for the developer. It has a great story for policies, but not for data. The best way to express the data that you need for authorization - user data, resource data, and information about the relationship between them - is with the Zanzibar ReBAC model. But there were no services that let you support both approaches.
We launched Topaz, an open-source authorizer, late last year to address that need. It lets organizations enjoy the best of both worlds, OPA and Zanzibar, and use their policies and underlying data for authorization as they see fit.
Topaz is a great way for people to get started with authorization. You don't need anything for it besides Docker on your machine. You can run it in your environment and get started in five minutes.
Aserto is built on top of Topaz and provides a control plane that lets you centrally manage your users, policies, data, and decision logs. It’s for when you want a managed solution that unifies authorization across applications and services.
The architecture of modern access control
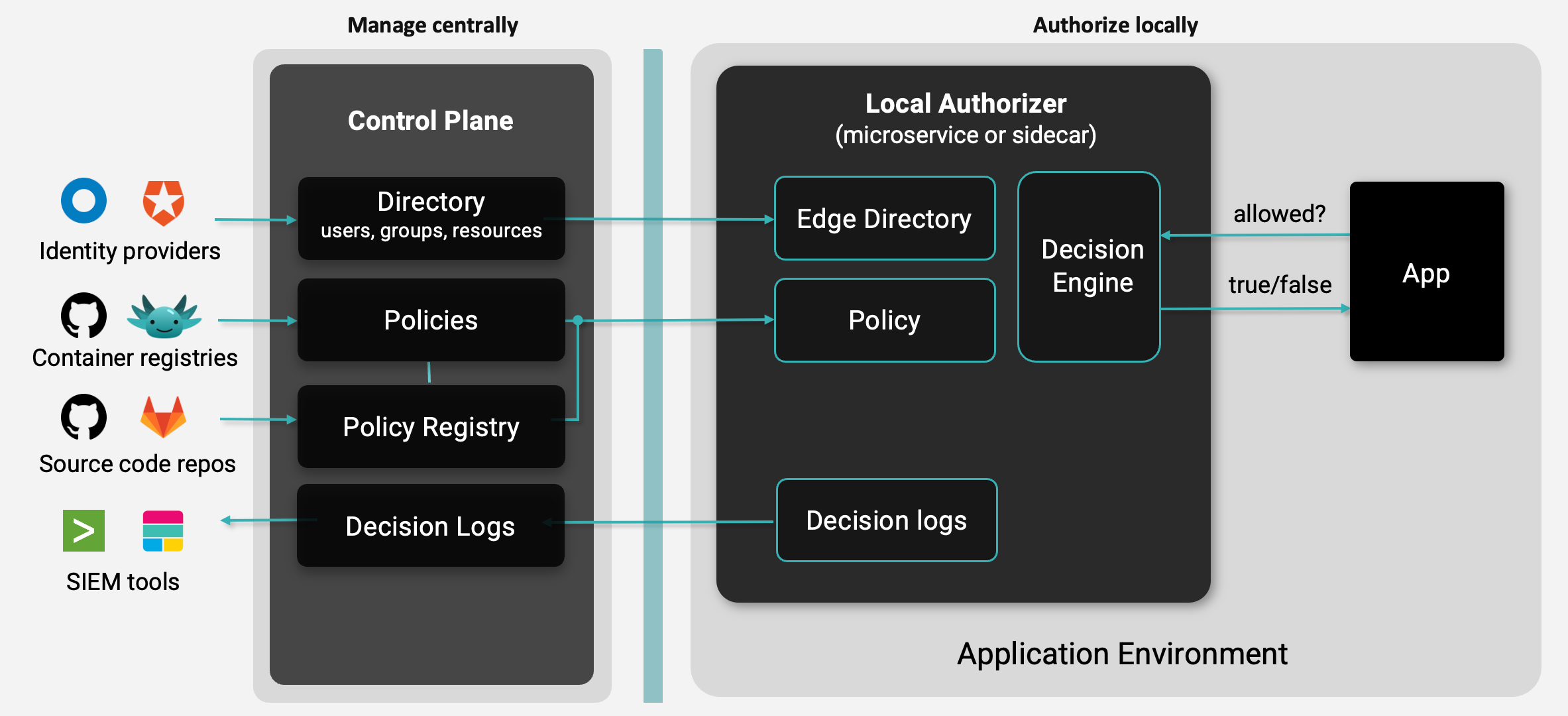
Access control is dynamic. Employees change teams and positions. External users share and update access to their data on an ongoing basis. So you have to enforce against the most up-to-date data, or risk authorizing over stale permissions.
Authorization is also in the critical path of every application request. Once the user is logged-in, calls go out all the time, as they click around. Applications send at least one, but oftentimes more than one, authorization call for every user interaction on their frontend. This means that the authorizer has to be local, otherwise you will spend precious time on round trip calls to a hosted authorization decision engine. The authorizer has to be local, it has to be a sidecar or a local language service that's running in your cloud, to avoid impacting user experience. By running the authorizer you can get down to millisecond enforcement times that are undetectable by the user. This is because the authorizer has all of the data that it needs to make a decision available locally.
Let’s walk through this. When an access request comes in you call the authorizer over gRPC or REST and it looks up the user in its embedded database based on a key- that's a constant-time operation. The authorizer already has the policy loaded. It will then load the resource and evaluate relationships by traversing the graph- this can be fulfilled very quickly. This is why local authorization is lightning-fast.
Making sure the local authorizers have the most updated information to enforce against is another challenge. And it’s a much harder challenge. Authorization based on real-time information requires a distributed system architecture. That is where the Aserto control plane comes in. It connects with every local authorizer and includes a data plane to sync changes to users, policies, or data with local authorizers over a high speed data fabric. Anytime a user attribute changes, or a policy changes, the control plane shares the new information with all the local authorizers, ensuring they have the latest policy and data. Then, when it comes time to make an authorization decision, the authorizers can make it locally in milliseconds.
Conclusion
The modern authorization landscape is confusing. There are two approaches to it that are growing ecosystems around them: the OPA policy-based approach and the Zanzibar data-centric approach.
The OPA approach gives you the most flexibility and is great for ABAC style authorization. It is best suited for applications with low levels of changes to the information they enforce against, as it does not have a data plane. The Zanzibar approach, on the other hand, is based on the application’s underlying data and built for scale. It’s an opinionated approach that provides the finest-level of control for applications that can map their resource hierarchy to tuples.
Topaz is an open-source tool that marries the two approaches, offering developers the best of both worlds. Grab the code to try it for yourself here.
Noa Shavit
Head of Marketing


Related Content

Cloud-native authorization on Category Visionaries
Aserto CEO, Omri Gazitt, joins Brett Stapper on the Category Visionaries podcast, a podcast that explores the visions for the future of founders who are on the front lines building it. Omri shares his entrepreneur journey and why he believes authorization is the next IAM frontier.
May 31st, 2023

Five common application authorization patterns
Authorization is complex because every app has to invent its own authorization model. Yet there are some well-worn paths which can be good starting points for most applications. In this post, we share five common authorization patterns, starting from the simplest IDP-based RBAC and culminating in a combination of group-based RBAC with fine-grained permissions and resources.
Jul 12th, 2023
“Auth” demystified: authentication vs authorization
Authentication and authorization are two processes that protect your applications against a damaging breach. Authentication guards the front gate, and authorization guards the various rooms in the house, limiting the potential blast radius by restricting what users can do. While the two work together, they are very different. In the post, we cover the main differences between application authorization and user authentication.
Jul 26th, 2023