&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
Centralized vs Distributed Authorization
Jan 24th, 2025

Omri Gazitt
Authorization |
DevOps
Introduction
In a previous post, we made the case for centralizing authorization as a workload. But even when authorization is treated as a centrally managed platform, there are architectural considerations for whether the authorizer runs centrally or in a distributed fashion, and where the data used for authorization resides.
In this follow-up article, we’ll discuss the deployment patterns for authorization systems, the tradeoffs between them, and an attractive middle ground.
If you haven’t read the previous article, it can be helpful background reading to understand why it makes sense to externalize authorization. This article assumes that you’ve decided to treat authorization as a separate concern, and it is primarily intended for architects who want to reason about the deployment models and their tradeoffs.
Authorization = policy + data
Just like any form of processing, authorization is performed by evaluating logic (typically in the form of a policy) over data (the inputs into the policy - such as user attributes, group memberships, or resource ownership).
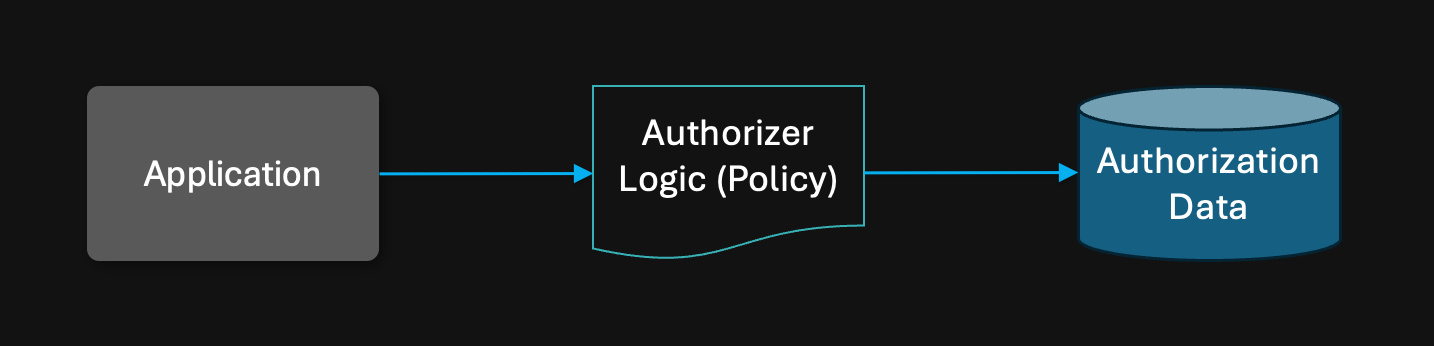
The deployment model for these three elements is critical to get right. Where to place network boundaries in the deployment model can have far-reaching effects across four dimensions:
- Latency: authorization is a latency-sensitive workload that must be executed in milliseconds.
- Throughput: scaling the deployment to meet high throughput requirements can be done at the logic layer, data layer, or both.
- Consistency: scaling the data layer can mean having to pick between transactional and eventual consistency.
- Management & Operations: distributed deployments require managing each authorizer as well as a strategy for central management of data, policy, and decision logs.
The rest of this article goes through the details of each deployment model, and grades them on these dimensions.
Centralized service
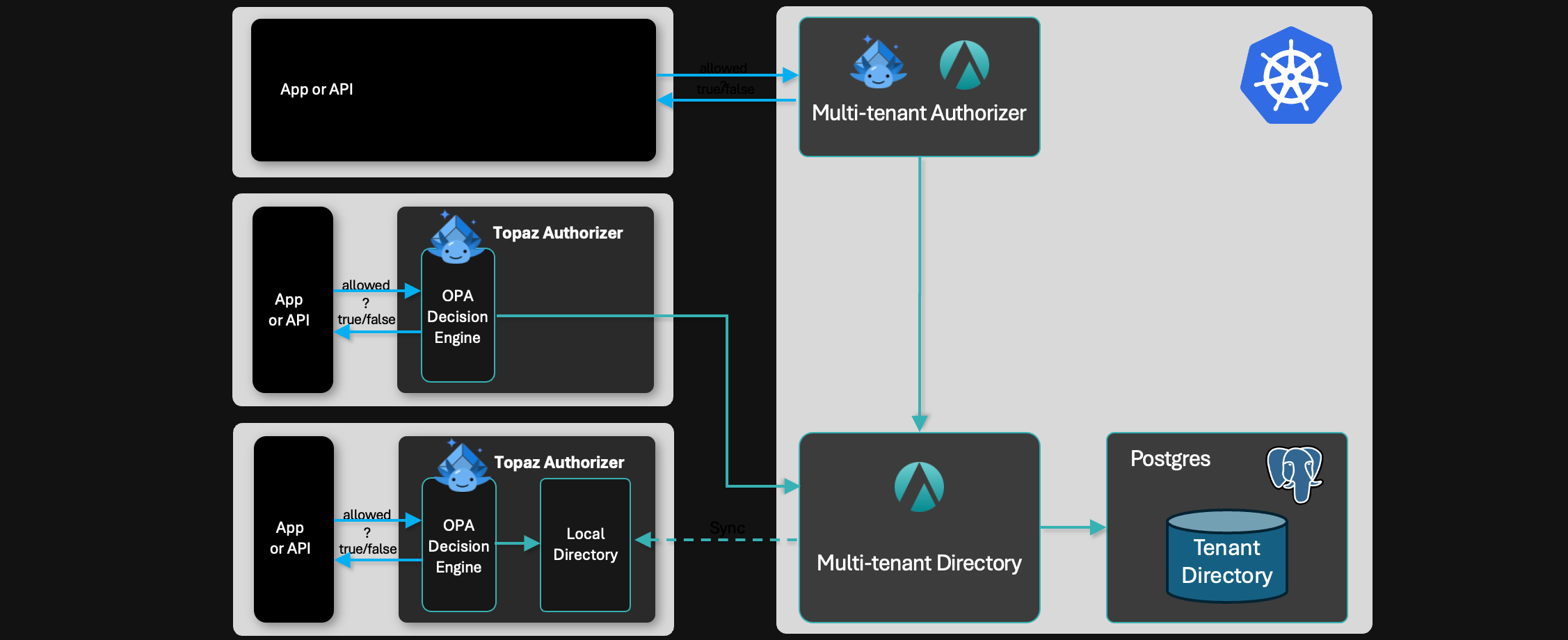
A centralized service is the most straightforward deployment model. Each application is configured to call a single deployment for its authorization requests.
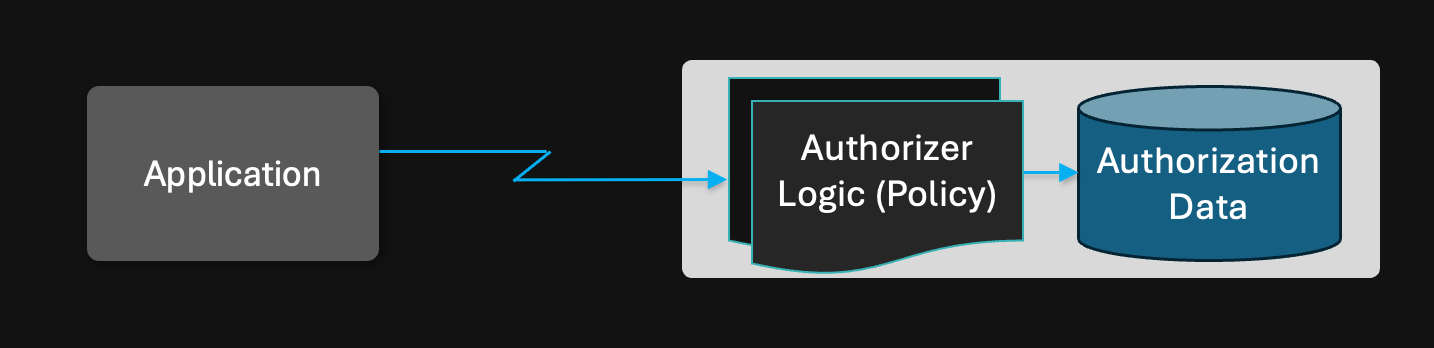
Stateful authorization systems, such as Zanzibar-based products, typically employ this deployment model.
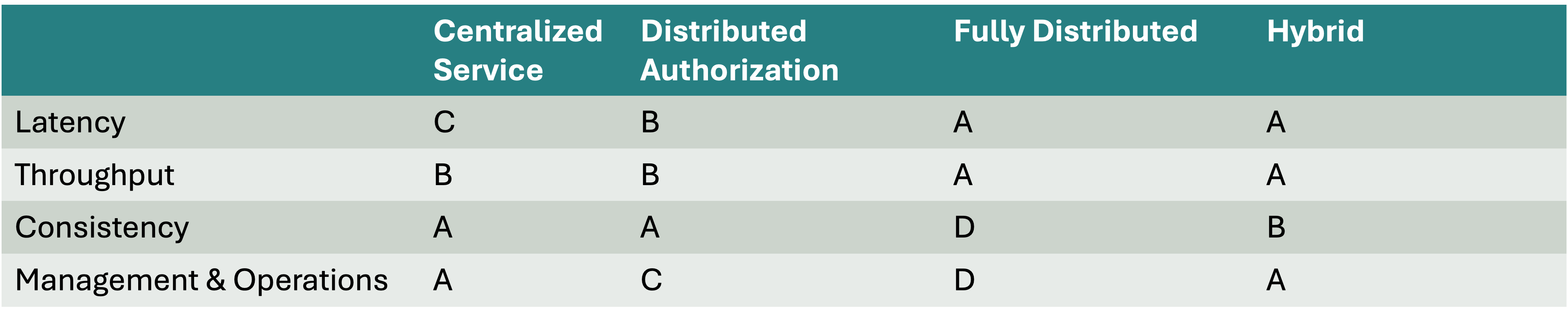
Latency: C
The main disadvantage of this deployment model is the added latency for evaluating authorization requests. Since the Authorizer is a network hop away from the application, and the database is another network hop from the Authorizer, latencies are typically measured in 10s of milliseconds, even when the system runs in the same cloud tenant as the application.
Throughput: B
A centralized service can be scaled by adding more replicas of the Authorizer service, each talking to the same database. The database, in turn, can be scaled up or out, depending on the throughput requirements and data size.
Ultimately, the scaling limits of this architecture depend on the data tier. Getting to millions of RPS requires utilizing a specialized data tier that can horizontally scale with the load.
Consistency: A
The centralized service deployment model has a single data store, which can be scaled using the cloud provider’s strategy for database scalability. For example, CloudSQL, Aurora, or CockroachDB can seamlessly scale data across nodes and regions.
Therefore, the centralized deployment model can offer transactional consistency for its consumers.
Management & Operations: A
A centralized service needs to be configured with a database connection and deployed into a Kubernetes cluster via a Helm chart or using the cloud provider’s deployment system (CloudFormation, Azure Resource Manager, etc.).
A centralized service is also a natural collection point for the policy logic and decision logs.
Distributed authorization
Some applications require scaling out the authorization layer with the application. In these models, the application and authorizer are deployed as a single Kubernetes pod.
The Authorizer can be configured to retrieve data from a remote store as part of its policy execution. For example, an OPA authorizer runs a policy that makes an HTTP call to a remote data source (including a Zanzibar system). Another example is Topaz configured to use a Postgres-backed directory service, which it can call remotely over a gRPC connection.

Latency: B
Co-locating the authorizer logic in the same pod as the application leads to best-case latency - typically in the range of 500µs to 1-2 milliseconds. This, of course, assumes that all the data is local, but if the Authorizer has to acquire its data from external data source, that latency must be taken into account.
Removing the network hop between the application and the authorizer logic helps bring down overall latency, but if the external data source is a Zanzibar product, the overall latency approximates latency for those systems (25-50ms).
Throughput: B
This deployment model scales the authorization throughput along with the application - so as the application auto-scales to more pods, the authorization throughput scales with it.
As with the centralized model, the bottleneck for scaling is the data tier.
Consistency: A
Since the data is still centralized, this deployment model offers transactional consistency.
Management & Operations: C
In addition to deploying and managing the central service, this model requires adding an Authorizer image to the application pod and configuring that Authorizer to talk to the external data source(s).
Also, authorization policy changes must be pulled (or pushed) to the distributed Authorizer(s), and decision logs need to be transmitted to a central service and aggregated. These are “exercises left to the reader.”
Fully Distributed (authorization + data)
Some applications have stringent latency and throughput requirements that require the co-location of the application, authorization logic, and data.
An example of this model is using an OPA sidecar that stores all of its data in a data.json file, or using Topaz with its local embedded database.
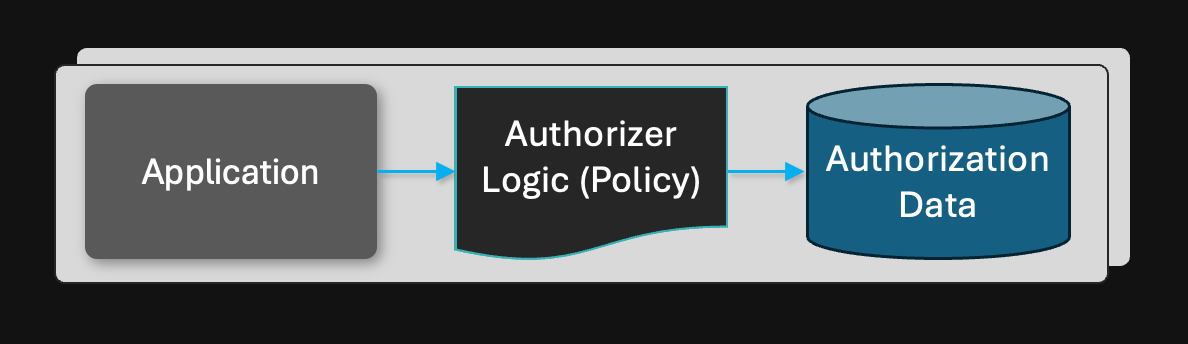
Latency: A
Since the application, authorization logic, and data are all co-located, this deployment model optimizes for the best latency. Authorization can be performed in the range of 500µs to a couple of milliseconds, depending on the complexity of the logic and the size of the data.
Throughput: A
Since each pod contains all the logic and data it needs to perform authorization locally, this model scales horizontally in a linear fashion. Adding more pods provides more throughput. However, if the data size exceeds what can fit in the local store, a data management strategy needs to be devised. For example, the data may need to be sharded across replicas.
Consistency: D
This deployment strategy requires careful design for how data is distributed across replicas. If data in each replica is unique (and each replica is the source of truth for its data), then each replica provides transactional consistency over the data it manages.
However, if the replicas share data or if each shard needs to be hosted in more than one pod for redundancy, then consistency becomes a problem. In that model, a change must be made in more than one pod simultaneously. This can be done transactionally or using an eventually consistent model, but it is a substantial amount of work for the application.
Management & Operations: D
This deployment model is entirely sidecar-based, so each application needs to have the Authorizer (e.g., Topaz or OPA) deployed in the same pod as the application.
However, policy changes, data management, and decision-log aggregation are “an exercise left to the reader.” These need to be built by hand or risk having a system that is not manageable in practice.
Hybrid: distributed execution, centralized management
So far, we’ve seen a set of tradeoffs between centralized systems and distributed deployment models. Centralized systems are generally easier to manage, whereas distributed deployments excel at providing low latency and linear scaling.
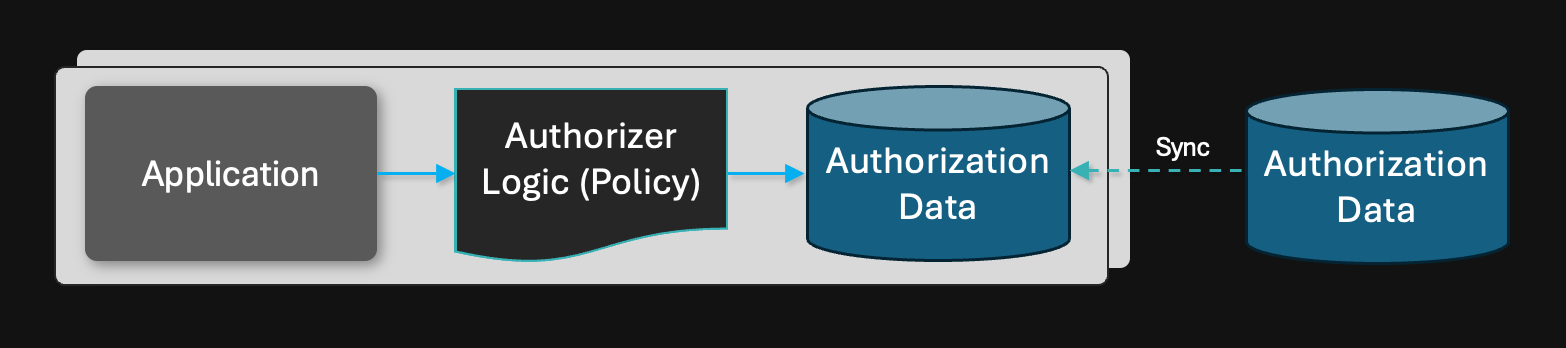
An attractive middle ground is to combine these ideas into a system that provides both the authorization logic and data co-located with the application for fast execution. However, the source of truth for the policy and authorization data is a centralized control plane.
Latency: A
The execution model is identical to the “Fully distributed” model, delivering the same excellent latency.
Throughput: A
Likewise, this model scales linearly with load, identical to the “Fully distributed” model.
Consistency: B
A centralized store acts as the “source of truth” for the authorization data, and data changes are made to this store, which is then delivered to each replica. This vastly simplifies the application's design but means an eventual consistency model for authorization data.
Management & Operations: A
Data, policy, and decision logs can be centralized in this hybrid architecture. Each distributed authorizer must be configured to be managed by the centralized “control plane.” The control plane is the control point for policy and data changes and the point of aggregation for decision logs.
Conclusion
This post delved into the tradeoffs between four deployment models. Here is the final report card for these models:
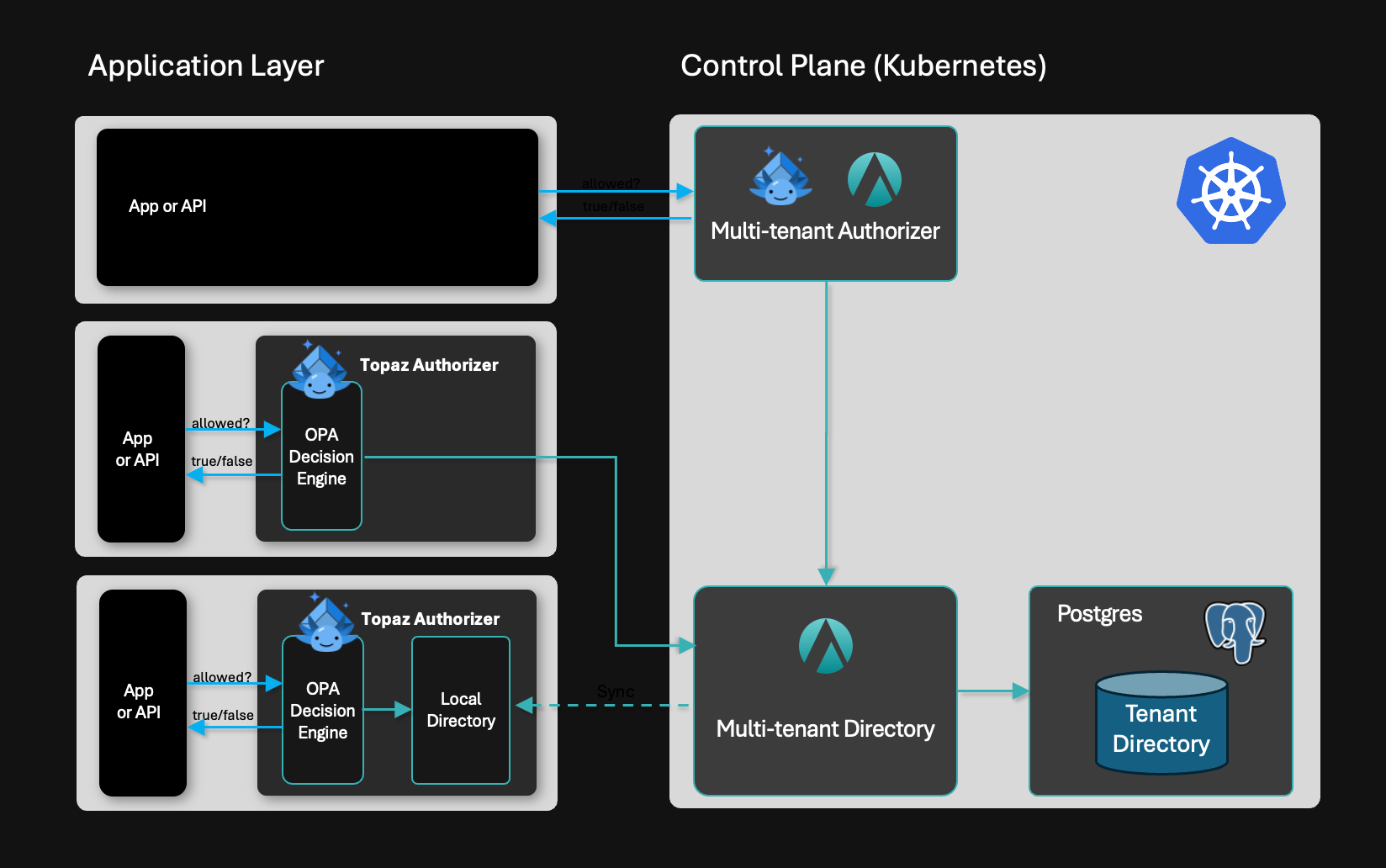
Aserto provides a set of building blocks that make it possible to implement any of these deployment models:
- Centralized service: a multi-tenant Topaz-based authorizer you can self-host in your Kubernetes cluster and a centralized (Postgres-backed) directory/data store.
- Distributed authorization: Topaz can be configured to talk to the Aserto multi-tenant directory.
- Fully distributed: Topaz can be configured to use its local directory for best-in-class latency.
- Hybrid: Topaz instances can be managed by the Aserto control plane to get the best of both worlds - local execution and centralized management.
If you’d like to learn more about authorization architectures or discuss your specific challenge, please join our Community Slack, contact us here, or schedule a video call with one of our engineers!
Omri Gazitt
CEO, Aserto


Related Content

Stateless vs Stateful Authorization
The most important design decision for an authorization system is how to bring data to the engine. Read all about the tradeoffs.
Mar 28th, 2025

The Case for Centralizing Authorization
Why centralize authorization, what are the impediments, and how do you overcome them?
Jan 9th, 2025

Authorization in 2024: Year in Review
As we ring in the new year, here’s a retrospective on authorization in 2024.
Dec 31st, 2024