&color=rgb(100%2C100%2C100)&link=https%3A%2F%2Fgithub.com%2Faserto-dev%2Ftopaz)
Building Permission-Aware Enterprise Chatbots
Nov 6th, 2024

Omri Gazitt
Authorization |
ReBAC
Chat as the new UX
Ever since ChatGPT introduced a conversational UI paradigm for AI-assisted information retrieval, we’ve all been re-imagining how to better serve our customers and employees using this approach.
A good example is enabling employees to ask questions that can be answered using a company’s unique dataset. And indeed, building enterprise chatbots that can combine the power of LLMs and use your corporate data is a hot topic right now. But how do you get your chatbot to respect the permissions that people have to various documents across your enterprise?
This post delves into how to build an access-control aware chatbot. And if you’d rather watch it in action, check out the demo!
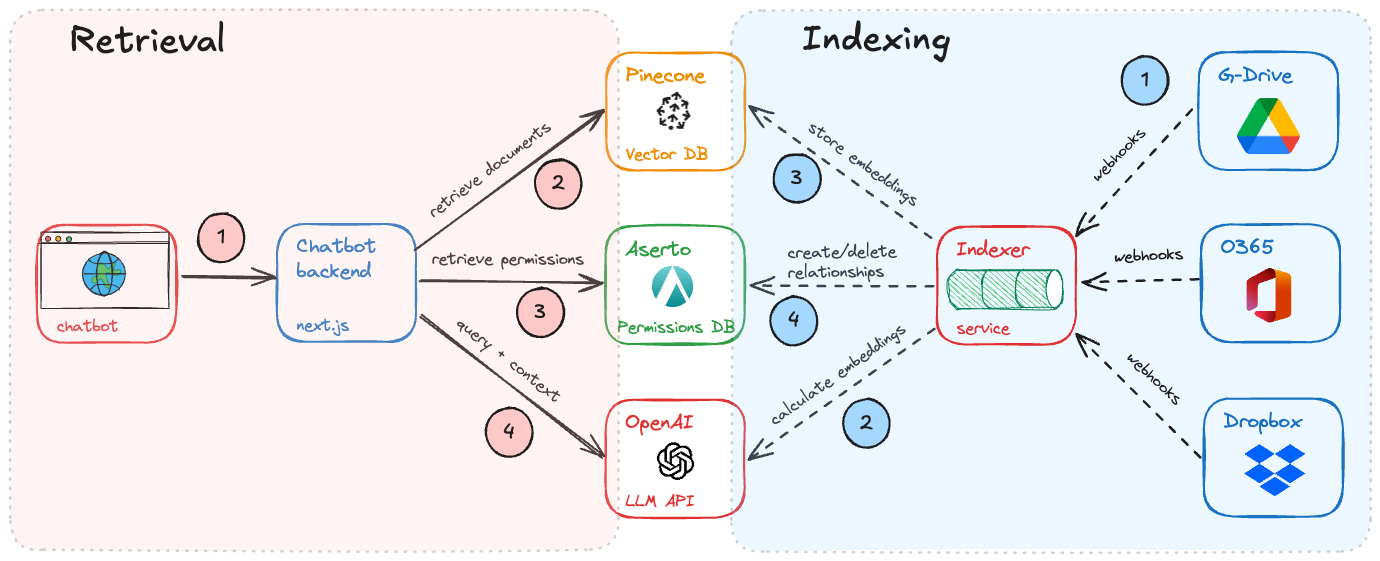
Building a permission-aware chatbot
This walkthrough is based on some excellent work that our friends at Pinecone did, combining their vector database and our permissioning system. Thanks Pinecone!
The technique we’re going to explore is called retrieval-augmented generation, or RAG for short. With RAG, you can use an “off the shelf” LLM like OpenAI to generate an answer to a user query, but you provide some of your company-specific data as part of the context that you inject into the request.
Let’s look at this in action.
Indexing
Much like techniques like pre-training or fine-tuning, RAG requires a pre-processing phase before user queries can be processed. The indexing phase involves a few steps.
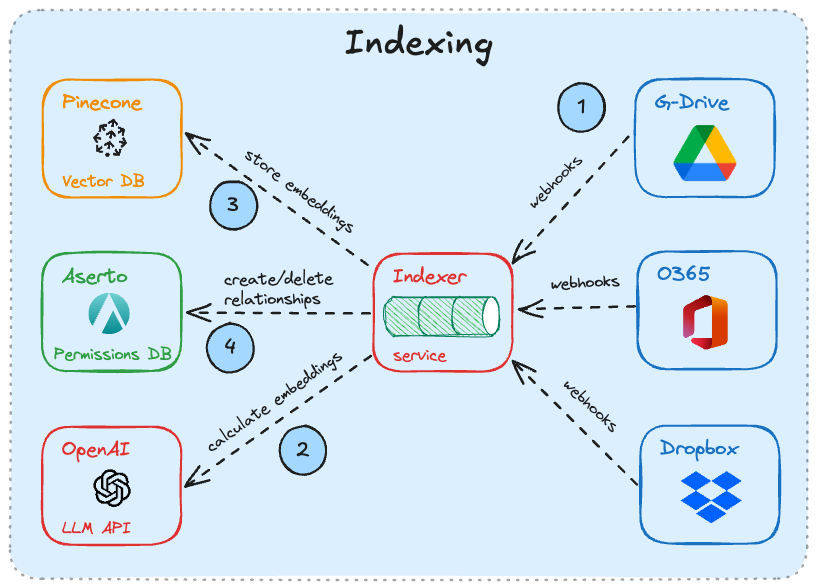
Computing embeddings
Embeddings are representations of a textual document in the form of large vectors of numbers. Textual blocks that are “close in meaning” have similar embeddings.
Vector databases are good at storing documents along with their embeddings, and being able to answer a query by returning the documents that are most relevant to that query, based on these embeddings.
The first step in the indexing phase is to compute embeddings for each of the enterprise resources (documents, CRM systems, wiki pages) that provide relevant data for the chatbot. This is typically done using a language model such as OpenAI Ada, Cohere Embed, or the open source E5 model. A chunk of text goes in, and an embedding comes out.
Storing embeddings in a vector database
Next, the embeddings are stored in a database such as Pinecone. We typically store the text, embedding, and any other metadata that we’d like to associate with that record. Examples could include the origin system, department that the data is associated with, or other attributes that may be relevant to restricting the use of that data to only certain classes of users.
Storing document permissions in a permissions database
Finally, if the document is locked down to specific users or groups, the access control list associated with that document is stored in a permissions database such as Aserto / Topaz. This is to prevent access violations - chatbots should never return answers that are based on data that the user cannot normally access.
Rinse and repeat
Documents and their permissions change all the time. For the chatbot to be useful, it should re-index corporate document systems on a schedule. Just as importantly, if a user loses access to a document, the index should be updated immediately, so that the chatbot can no longer use that document as a source of answers for that user.
This is easier to do when the system includes a callback mechanism (such as webhooks) that sends a notification when a document or its associated permissions change.
Retrieval and generation
Once we’ve taken care of the indexing phase, we can turn our attention to retrieval and generation. This is essentially the same process, in reverse.
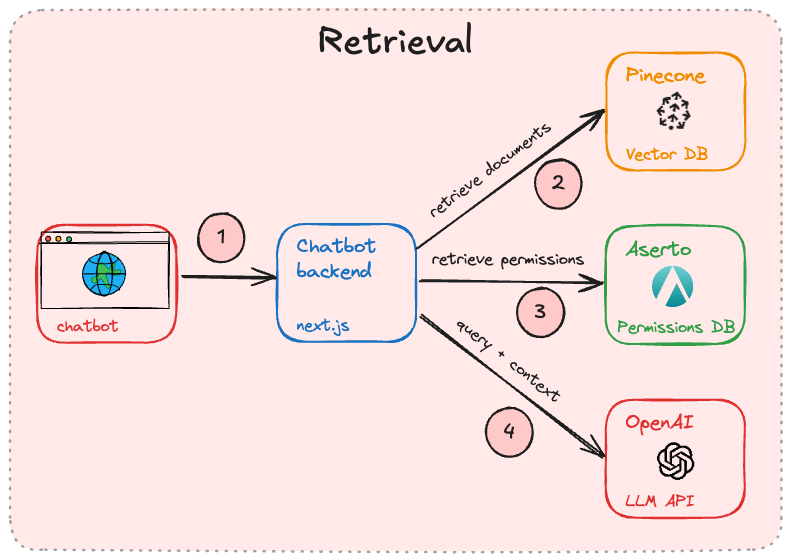
Compute an embedding for the user’s query
As the user types a question into the chatbot, an embedding is computed for that query. This can be done using the same AI model that was used during the indexing phase.
Retrieve related documents
Vector databases are good at returning documents that are semantically close to a query. We can then send the query/embedding to a vector database such as Pinecone, and get back a set of documents that match the intent of the query. Typically, the top 10 results are sufficient to augment the query with enterprise-specific context.
Filter the results based on permissions
The candidate results must then be filtered down to only the documents that a user can normally access. This is done by issuing a query to a permissions database such as Aserto / Topaz, which is built to answer questions like “does this user have this permission on this document”.
Generate a response using the LLM
Finally, the user’s query is augmented with the documents that pass the filtering phase and sent to an LLM such as OpenAI, which can formulate a natural-language answer to the query, and utilize the enterprise-specific context in its response.
Call to action
While the process described in this article is straightforward, the devil is in the details. The hardest problem in building the indexing system is keeping a real-time record of who has access to what documents. When a user loses access, the permissions system needs to be updated to reflect this.
Aserto has built some connectors that help with this. Building a chatbot for your enterprise and need some help? Schedule some time with us!
Omri Gazitt
CEO, Aserto


Related Content

Cloud-Native Authorization at KubeCon NA 2024
KubeCon 2024 in Salt Lake City felt like an inflection point for cloud-native authorization. Here are some reasons why.
Nov 24th, 2024

Authorization at Gartner IAM Summit 2024
Gartner IAM Summit is one of the top events in the identity universe, and Authorization is becoming a key pillar. Here’s our trip report.
Dec 13th, 2024

Authorization in 2024: Year in Review
As we ring in the new year, here’s a retrospective on authorization in 2024.
Dec 31st, 2024